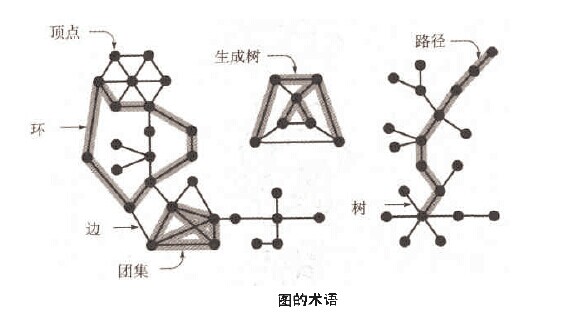
图的定义:
图(graph)由顶点(vertex)和边(edge)的集合组成,每一条边就是一个点对(v,w)。
图的种类:地图,电路图,调度图,事物,网络,程序结构
图的属性:有V个顶点的图最多有V*(V-1)/2条边
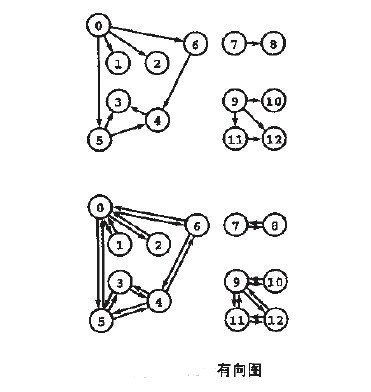
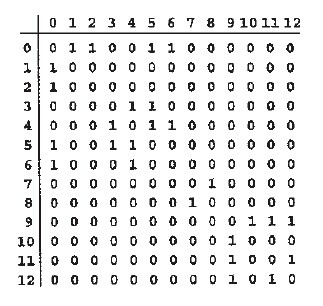
邻接矩阵:
邻接矩阵是一个元素为bool值的VV矩阵,若图中存在一条连接顶点V和W的边,折矩阵adj[v][w]=1,否则为0。占用的空间为VV,当图是稠密时,邻接矩阵是比较合适的表达方法。
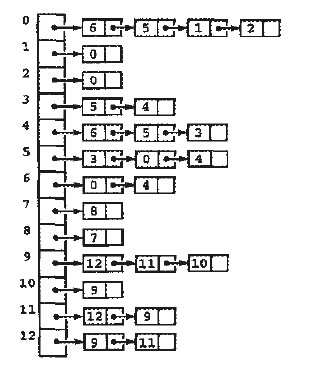
邻接表的表示
对于非稠密的图,使用邻接矩阵有点浪费存储空间,可以使用邻接表,我们维护一个链表向量,给定一个顶点时,可以立即访问其链表,占用的空间为O(V+E)。
深度优先搜索
深度优先搜索介绍
图的深度优先搜索(Depth First Search),和树的先序遍历比较类似。
它的思想:假设初始状态是图中所有顶点均未被访问,则从某个顶点v出发,首先访问该顶点,然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和v有路径相通的顶点都被访问到。 若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
显然,深度优先搜索是一个递归的过程。
深度优先搜索图解
无向图的深度优先搜索
下面以”无向图”为例,来对深度优先搜索进行演示。
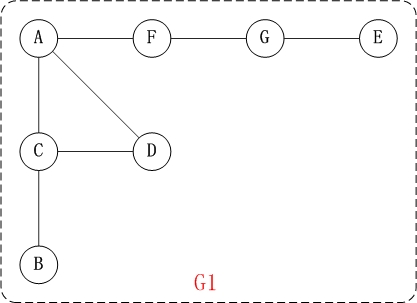
对上面的图G1进行深度优先遍历,从顶点A开始。
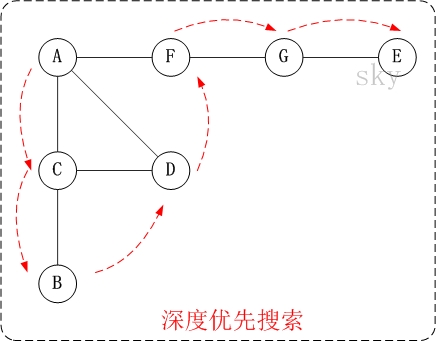
- 第1步:访问A。
第2步:访问(A的邻接点)C。
在第1步访问A之后,接下来应该访问的是A的邻接点,即”C,D,F”中的一个。但在本文的实现中,顶点ABCDEFG是按照顺序存储,C在”D和F”的前面,因此,先访问C。
第3步:访问(C的邻接点)B。
在第2步访问C之后,接下来应该访问C的邻接点,即”B和D”中一个(A已经被访问过,就不算在内)。而由于B在D之前,先访问B。
第4步:访问(C的邻接点)D。
在第3步访问了C的邻接点B之后,B没有未被访问的邻接点;因此,返回到访问C的另一个邻接点D。
第5步:访问(A的邻接点)F。
前面已经访问了A,并且访问完了”A的邻接点B的所有邻接点(包括递归的邻接点在内)”;因此,此时返回到访问A的另一个邻接点F。
第6步:访问(F的邻接点)G。
第7步:访问(G的邻接点)E。
因此访问顺序是:A -> C -> B -> D -> F -> G -> E
有向图的深度优先搜索
下面以”有向图”为例,来对深度优先搜索进行演示。
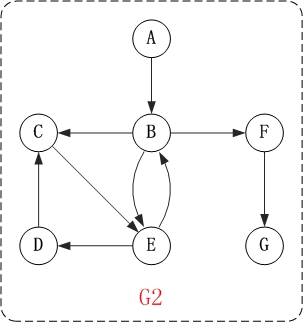
对上面的图G2进行深度优先遍历,从顶点A开始。
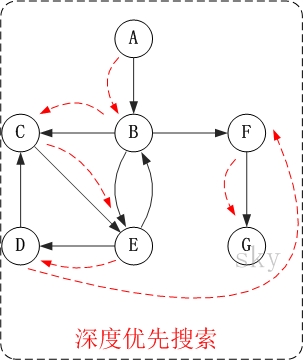
第1步:访问A。
第2步:访问B。
在访问了A之后,接下来应该访问的是A的出边的另一个顶点,即顶点B。
第3步:访问C。
在访问了B之后,接下来应该访问的是B的出边的另一个顶点,即顶点C,E,F。在本文实现的图中,顶点ABCDEFG按照顺序存储,因此先访问C。
第4步:访问E。
接下来访问C的出边的另一个顶点,即顶点E。
第5步:访问D。
接下来访问E的出边的另一个顶点,即顶点B,D。顶点B已经被访问过,因此访问顶点D。
第6步:访问F。
接下应该回溯”访问A的出边的另一个顶点F”。
第7步:访问G。
因此访问顺序是:A -> B -> C -> E -> D -> F -> G
广度优先搜索
广度优先搜索介绍
广度优先搜索算法(Breadth First Search),又称为”宽度优先搜索”或”横向优先搜索”,简称BFS。
它的思想是:从图中某顶点v出发,在访问了v之后依次访问v的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使得“先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问,直至图中所有已被访问的顶点的邻接点都被访问到。如果此时图中尚有顶点未被访问,则需要另选一个未曾被访问过的顶点作为新的起始点,重复上述过程,直至图中所有顶点都被访问到为止。
换句话说,广度优先搜索遍历图的过程是以v为起点,由近至远,依次访问和v有路径相通且路径长度为1,2…的顶点。
广度优先搜索图解
无向图的广度优先搜索
下面以”无向图”为例,来对广度优先搜索进行演示。还是以上面的图G1为例进行说明。
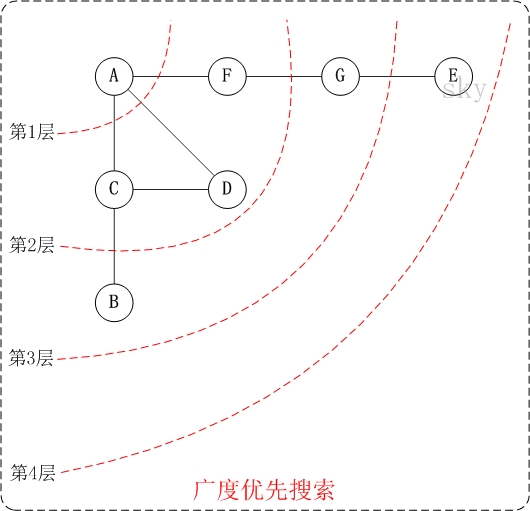
- 第1步:访问A。
第2步:依次访问C,D,F。
在访问了A之后,接下来访问A的邻接点。前面已经说过,在本文实现中,顶点ABCDEFG按照顺序存储的,C在”D和F”的前面,因此,先访问C。再访问完C之后,再依次访问D,F。
第3步:依次访问B,G。
在第2步访问完C,D,F之后,再依次访问它们的邻接点。首先访问C的邻接点B,再访问F的邻接点G。
第4步:访问E。
在第3步访问完B,G之后,再依次访问它们的邻接点。只有G有邻接点E,因此访问G的邻接点E。
因此访问顺序是:A -> C -> D -> F -> B -> G -> E
有向图的广度优先搜索
下面以”有向图”为例,来对广度优先搜索进行演示。还是以上面的图G2为例进行说明。
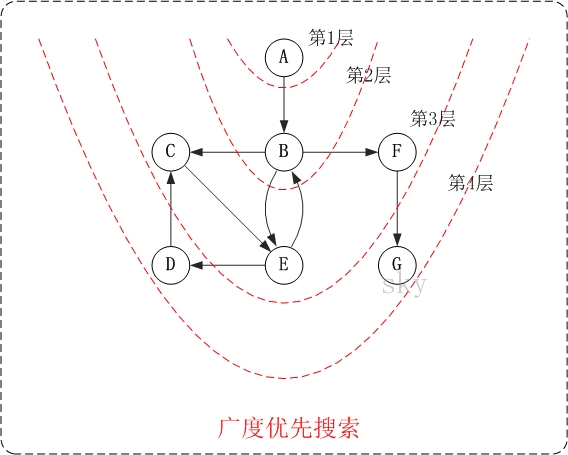
第1步:访问A。
第2步:访问B。
第3步:依次访问C,E,F。
在访问了B之后,接下来访问B的出边的另一个顶点,即C,E,F。前面已经说过,在本文实现中,顶点ABCDEFG按照顺序存储的,因此会先访问C,再依次访问E,F。
第4步:依次访问D,G。
在访问完C,E,F之后,再依次访问它们的出边的另一个顶点。还是按照C,E,F的顺序访问,C的已经全部访问过了,那么就只剩下E,F;先访问E的邻接点D,再访问F的邻接点G。
因此访问顺序是:A -> B -> C -> E -> F -> D -> G
搜索算法的源码
1. 邻接矩阵表示的”无向图
1 | /** |
2. 邻接表表示的”无向图
1 | /** |
迪杰斯特拉算法
迪杰斯特拉(Dijkstra)算法是典型最短路径算法,用于计算一个节点到其他节点的最短路径。
它的主要特点是以起始点为中心向外层层扩展(广度优先搜索思想),直到扩展到终点为止。
基本思想
通过Dijkstra计算图G中的最短路径时,需要指定起点s(即从顶点s开始计算)。
此外,引进两个集合S和U。S的作用是记录已求出最短路径的顶点(以及相应的最短路径长度),而U则是记录还未求出最短路径的顶点(以及该顶点到起点s的距离)。
初始时,S中只有起点s;U中是除s之外的顶点,并且U中顶点的路径是”起点s到该顶点的路径”。然后,从U中找出路径最短的顶点,并将其加入到S中;接着,更新U中的顶点和顶点对应的路径。 然后,再从U中找出路径最短的顶点,并将其加入到S中;接着,更新U中的顶点和顶点对应的路径。 … 重复该操作,直到遍历完所有顶点。
操作步骤
(1)
初始时,S只包含起点s;U包含除s外的其他顶点,且U中顶点的距离为”起点s到该顶点的距离”[例如,U中顶点v的距离为(s,v)的长度,然后s和v不相邻,则v的距离为∞]。
(2) 从U中选出”距离最短的顶点k”,并将顶点k加入到S中;同时,从U中移除顶点k。
(3)
更新U中各个顶点到起点s的距离。之所以更新U中顶点的距离,是由于上一步中确定了k是求出最短路径的顶点,从而可以利用k来更新其它顶点的距离;例如,(s,v)的距离可能大于(s,k)+(k,v)的距离。
(4) 重复步骤(2)和(3),直到遍历完所有顶点。
单纯的看上面的理论可能比较难以理解,下面通过实例来对该算法进行说明。
5.3迪杰斯特拉算法图解
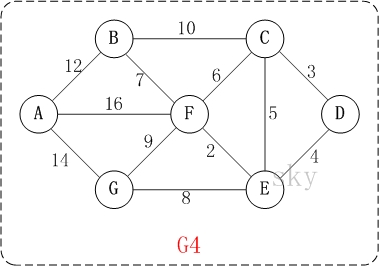
以上图G4为例,来对迪杰斯特拉进行算法演示(以第4个顶点D为起点)。
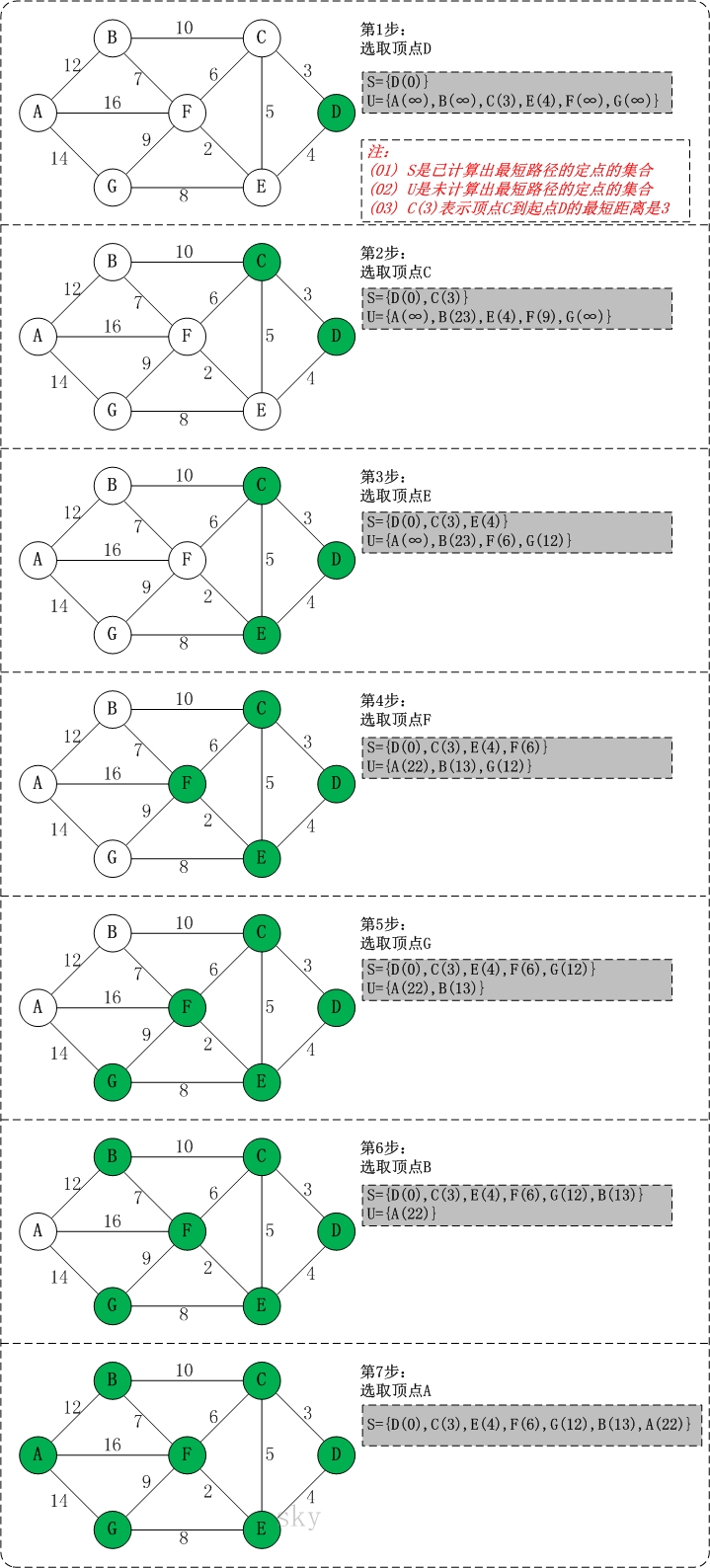
初始状态:S是已计算出最短路径的顶点集合,U是未计算除最短路径的顶点的集合!
第1步:将顶点D加入到S中。
此时,S={D(0)}, U={A(∞),B(∞),C(3),E(4),F(∞),G(∞)}。 注:C(3)表示C到起点D的距离是3。
第2步:将顶点C加入到S中。
上一步操作之后,U中顶点C到起点D的距离最短;因此,将C加入到S中,同时更新U中顶点的距离。以顶点F为例,之前F到D的距离为∞;但是将C加入到S之后,F到D的距离为9=(F,C)+(C,D)。
此时,S={D(0),C(3)}, U={A(∞),B(23),E(4),F(9),G(∞)}。第3步:将顶点E加入到S中。
上一步操作之后,U中顶点E到起点D的距离最短;因此,将E加入到S中,同时更新U中顶点的距离。还是以顶点F为例,之前F到D的距离为9;但是将E加入到S之后,F到D的距离为6=(F,E)+(E,D)。
此时,S={D(0),C(3),E(4)}, U={A(∞),B(23),F(6),G(12)}。
第4步:将顶点F加入到S中。
此时,S={D(0),C(3),E(4),F(6)}, U={A(22),B(13),G(12)}。
第5步:将顶点G加入到S中。
此时,S={D(0),C(3),E(4),F(6),G(12)}, U={A(22),B(13)}。
第6步:将顶点B加入到S中。
此时,S={D(0),C(3),E(4),F(6),G(12),B(13)}, U={A(22)}。
第7步:将顶点A加入到S中。
此时,S={D(0),C(3),E(4),F(6),G(12),B(13),A(22)}。
此时,起点D到各个顶点的最短距离就计算出来了:A(22) B(13) C(3) D(0) E(4) F(6) G(12)。
代码
本文以”邻接矩阵”为例对迪杰斯特拉算法进行说明,
基本定义
1 | // 邻接矩阵 |
Graph是邻接矩阵对应的结构体。
vexs用于保存顶点,vexnum是顶点数,edgnum是边数;matrix则是用于保存矩阵信息的二维数组。例如,matrix[i][j]=1,则表示”顶点i(即vexs[i])”和”顶点j(即vexs[j])”是邻接点;matrix[i][j]=0,则表示它们不是邻接点。
EData是邻接矩阵边对应的结构体。
迪杰斯特拉算法
代码:
1 | /* |

