MySQL学习笔记(Day017:Explain_2)
@(MySQL学习)
[TOC]
一. 作业解析
- 哪张原数据表中记录了Cardinality信息
1 | -- |
- 检查表的索引创建的情况,判断该索引是否有创建的必要
1 | -- |
索引是要排序的,建立索引越多,排序以及维护成本会很大,插入数据的速度会变慢,所以索引建立的多,不是仅仅是浪费空间,还会降低性能,增加磁盘IO
注意:MySQL5.6的版本STATISTICS数据存在问题,截止5.6.28仍然存在,官方定性为Bug
作业一:在
MySQL5.6中使用mysql.innodb_index_stats得到索引的选择性(SELECTIVITY)
二. MySQL5.6安装sys库
1 | shell > git clone https://github.com/mysql/mysql-sys.git |
1 | mysql> select version(); |
三. Explain(二)
1. Explain输出介绍
| 列 | 含义 |
|---|---|
| id | 执行计划的id标志 |
| select_type | SELECT的类型 |
| table | 输出记录的表 |
| partitions | 符合的分区,[PARTITIONS] |
| type | JOIN的类型 |
| possible_keys | 优化器可能使用到的索引 |
| key | 优化器实际选择的索引 |
| key_len | 使用索引的字节长度 |
| ref | 进行比较的索引列 |
| rows | 优化器预估的记录数量 |
| filtered | 根据条件过滤得到的记录的百分比[EXTENDED] |
| extra | 额外的显示选项 |
(1). id
从上往下理解,不一定 id 序号大的先执行
可以简单的理解为 id 相等的从上往下看,id 相等的从下往上看。但是在某些场合也
不一定适用
(2). select_type
| select_type | 含义 |
|---|---|
| SIMPLE | 简单SELECT(不使用UNION或子查询等) |
| PRIMARY | 最外层的select |
| UNION | UNION中的第二个或后面的SELECT语句 |
| DEPENDENT UNION | UNION中的第二个或后面的SELECT语句,依赖于外面的查询 |
| UNION RESULT | UNION的结果 |
| SUBQUERY | 子查询中的第一个SELECT |
| DEPENDENT SUBQUERY | 子查询中的第一个SELECT,依赖于外面的查询 |
| DERIVED | 派生表的SELECT(FROM子句的子查询) |
| MATERIALIZED | 物化子查询 |
| UNCACHEABLE SUBQUERY | 不会被缓存的并且对于外部查询的每行都要重新计算的子查询 |
| UNCACHEABLE UNION | 属于不能被缓存的 UNION中的第二个或后面的SELECT语句 |
- MATERIALIZED
- 产生中间临时表(实体)
- 临时表自动创建索引并和其他表进行关联,提高性能
- 和子查询的区别是,优化器将可以进行
MATERIALIZED的语句自动改写成join,并自动创建索引
(3). table
- 通常是用户操作的用户表
- <unionM, N> UNION得到的结果表
排生表,由id=N的语句产生 由子查询物化产生的表,由id=N的语句产生
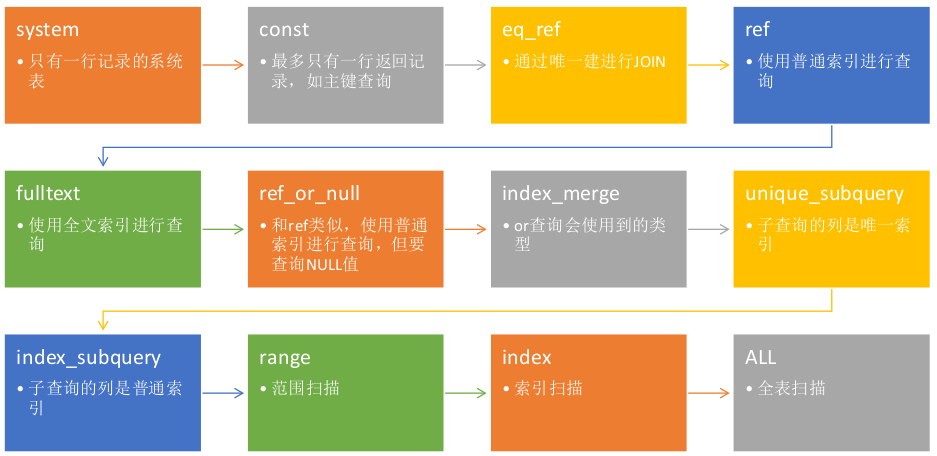
####(4). type
摘自姜老师的PDF,按照图上箭头的顺序来看,成本(cost)是从小到大
####(5). extra
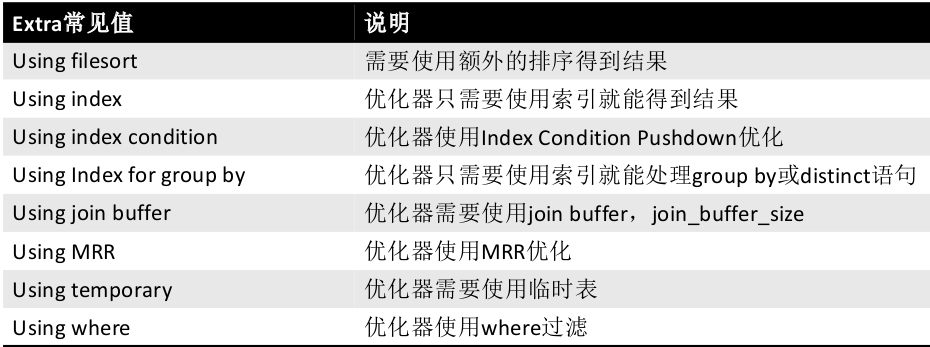
- Using filesort:可以使用复合索引将filesort进行优化。提高性能
- Using index:比如使用覆盖索引
- Using where: 使用where过滤条件
Extra的信息是可以作为优化的提示,但是更多的是优化器优化的一种说明

